
IA locale et privée avec Ollama et Open WebUI
Une façon simple et surtout abordable d'utiliser l'intelligence artificielle aujourd'hui, c'est de la déployer directement sur votre propre machine. Si vous avez la chance d'avoir un ordinateur équipé d'un GPU avec 6 Go de VRAM ou plus, vous possédez déjà tout le matériel nécessaire pour faire tourner des modèles d'IA extrêmement performants.
Le plus beau dans tout ça ? Vous pouvez le faire gratuitement, avec des outils open-source, et surtout : en gardant 100% de vos données privées. Dans un contexte où de plus en plus d'entreprises interdisent l'utilisation des IA publiques (comme Gemini, ChatGPT ou Claude) par peur de fuites de code source ou de données sensibles, avoir votre propre instance locale déconnectée d'internet vous rend l'esprit tranquille.
Pour pallier à ces limitations corporatives, nous allons jouer aux Lego un peu : Docker (ou Podman), Ollama (pour faire rouler les modèles) et Open WebUI (pour l'interface graphique).
Podman vs Docker : L'alternative sécuritaire
Avant de plonger dans les fichiers de configuration, parlons de l'engin de "containers". Le standard de l'industrie reste Docker, mais si vous êtes soucieux de la sécurité ou que vous travaillez dans un environnement très strict, Podman est une alternative formidable.
L'avantage principal de Podman est qu'il est daemonless (pas de processus d'arrière-plan lourd) et rootless (les conteneurs peuvent rouler sans les privilèges administrateurs). Pour l'installer sur Ubuntu, c'est très simple :
sudo apt update
sudo apt install podman podman-compose podman-docker
L'écosystème est tellement compatible que vous pouvez généralement faire un alias docker=podman et oublier que vous avez changé d'outil. Ceci dit, pour ce tutoriel, nos scripts pointeront sur Docker, mais la logique reste identique.
L'architecture : Le fichier docker-compose.yml
Afin de pouvoir déployer votre stack facilement, nous allons utiliser "Docker" Compose. Voici le fichier qui définit votre architecture :
services:
ollama:
volumes:
- ./ollama-data:/root/.ollama
container_name: ollama
tty: true
restart: unless-stopped
image: docker.io/ollama/ollama:latest
ports:
- 127.0.0.1:11434:11434
environment:
- OLLAMA_KEEP_ALIVE=24h
networks:
- ollama-docker
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
openwebui:
image: ghcr.io/open-webui/open-webui:cuda
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
ports:
- "127.0.0.1:3000:8080"
networks:
- ollama-docker
volumes:
- ./webui-data:/app/backend/data
networks:
ollama-docker:
external: false
Il y a quatre détails cruciaux dans cette configuration :
- L'accès au GPU : La section
deploy.resources.reservations.devicesavec le drivernvidiapermet à vos conteneurs d'utiliser votre carte graphique. Open WebUI utilise l'image:cudapour accélérer localement les modèles choisis. - Le maintien en mémoire : La variable d'environnement
OLLAMA_KEEP_ALIVE=24hest pseudo-magique. Par défaut, Ollama décharge le modèle de la VRAM après 5 minutes d'inactivité. Cette variable garde le modèle chargé pendant 24 heures, vous évitant d'attendre 10 secondes au prochain prompt. - Le lien entre WebUI et Ollama : Les deux services sont branchés sur le même réseau virtuel
ollama-docker. Open WebUI sait comment chercher Ollama s'ils partagent un réseau, garantissant une communication fluide sans exposer l'API d'Ollama au reste de votre réseau local (notez le127.0.0.1sur les ports). - Les volumes : Les données et les modèles seront sauvegardés dans le même dossier et vont persister à travers les sessions et les redémarrages.
Simplifier la gestion avec control.sh
Même si vous adorez taper les commandes Docker comme un fou, avoir un script de contrôle facilite et standardise vos opérations. Voici control.sh, un wrapper Bash tout simple :
#!/usr/bin/env bash
set -euo pipefail
# Constants
SCRIPT_NAME=$(basename "$0")
readonly SCRIPT_NAME
SCRIPT_DIR=$(cd "$(dirname "$0")" && pwd)
readonly SCRIPT_DIR
readonly LOG_FILE="${SCRIPT_DIR}/control.log"
# Global Variables
: "${VERBOSE:=false}"
# --- Core Functions ---
log() {
local level="${1:-INFO}"
shift
local timestamp
timestamp=$(date '+%Y-%m-%d %H:%M:%S')
local message="[$timestamp] [$level] $*"
echo -e "$message"
echo "$message" >> "$LOG_FILE"
}
info() { log "INFO" "$*"; }
error() { log "ERROR" "$*" >&2; exit 1; }
debug() {
if [[ "$VERBOSE" == "true" ]]; then
log "DEBUG" "$*"
fi
}
cleanup() {
local exit_code=$?
if [[ $exit_code -ne 0 ]]; then
log "ERROR" "Script exited with error code $exit_code"
fi
}
trap cleanup EXIT
check_dependencies() {
debug "Checking dependencies..."
for cmd in docker docker-compose; do
if ! command -v "$cmd" &> /dev/null; then
if [[ "$cmd" == "docker-compose" ]]; then
if ! docker compose version &> /dev/null; then
error "Dependency missing: $cmd (or docker compose plugin)"
fi
else
error "Dependency missing: $cmd"
fi
fi
done
}
show_help() {
cat << EOF
Usage: $SCRIPT_NAME [OPTIONS] [COMMAND] [ARGS...]
Manage Docker Compose services for Ollama.
Options:
-v, --verbose Enable verbose logging
-h, --help Show this help message
Commands:
start Start services (creates and starts containers)
stop Stop services (stops containers without removing them)
down Stop and remove containers, networks, and volumes
update Pull latest images and recreate containers
restart Restart services (stops and recreates containers)
logs Show logs
ollama Run an Ollama command (e.g., list, pull, rm)
help Show this help message
Examples:
$SCRIPT_NAME start
$SCRIPT_NAME -v update
$SCRIPT_NAME ollama list
$SCRIPT_NAME ollama pull llama3
EOF
}
# --- Service Commands ---
start_services() { info "Starting services..."; docker compose up -d; }
stop_services() { info "Stopping services..."; docker compose stop; }
down_services() { info "Stopping and removing services..."; docker compose down; }
update_services() { info "Updating services..."; docker compose pull; docker compose up -d --force-recreate; }
restart_services() { info "Restarting services..."; docker compose down; docker compose up -d --force-recreate; }
show_logs() { info "Showing logs..."; docker compose logs -f; }
run_ollama() {
local cmd="$1"
shift
info "Running Ollama command: $cmd $*"
if docker ps --filter "name=ollama" --filter "status=running" | grep -q ollama; then
debug "Ollama container is running. Executing command..."
docker exec -it ollama ollama "$cmd" "$@"
else
error "Ollama container is not running. Start services first."
fi
}
# --- Main Logic ---
main() {
cd "$SCRIPT_DIR"
while [[ $# -gt 0 ]]; do
case "$1" in
-v|--verbose) VERBOSE=true; shift ;;
-h|--help) show_help; exit 0 ;;
*) break ;;
esac
done
check_dependencies
if [[ $# -eq 0 ]]; then show_help; return 0; fi
local command="$1"
shift
case "$command" in
start) start_services ;;
stop) stop_services ;;
down) down_services ;;
update) update_services ;;
restart) restart_services ;;
logs) show_logs ;;
ollama) run_ollama "$@" ;;
help) show_help ;;
*) echo "Error: Unknown command '$command'"; show_help; exit 1 ;;
esac
}
main "$@"
Une fois le script rendu exécutable (chmod +x control.sh), vous lancez toute votre infrastructure simplement avec ./control.sh start.
Mais le véritable avantage pour moi réside dans la commande ollama intégrée. Au lieu de devoir trouver l'ID du conteneur et d'utiliser docker exec, vous pouvez directement taper ./control.sh ollama pull llama3.1:8b pour télécharger un modèle.
N'oubliez pas de configurer la connexion dans WebUi correctement:
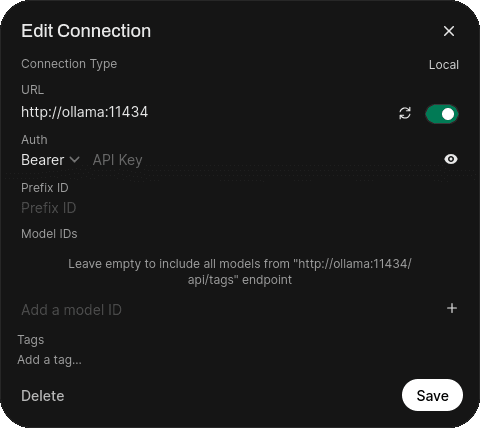
Oh! Pour accéder l'application, il suffit de se rendre sur http://localhost:3000/. Personnellement, j'utilise un addon pour Firefox, nommé PWAs for Firefox, qui fait en sorte que tout semble comme une application intégrée avec mon desktop Linux.
Les modèles gratuits et performants à privilégier
Avoir l'infrastructure, c'est bien, mais quels modèles faire tourner quand vous avez 6 Go de VRAM ? Voici une sélection que j'aime bien de mon côté:
gemma4:e2b: Parfait pour les machines avec des ressources limitées. Ce modèle optimisé (2,3 milliards de paramètres effectifs) est conçu spécifiquement pour les appareils comme les laptops mais est d'une puissance impressionnante… pour le code comme pour un peu n'importe quoi, c'est mon modèle par défaut.glm-ocr:latest: Un outil chirurgical. Avec seulement 0,9 milliard de paramètres, ce modèle excelle dans la reconnaissance optique de caractères (OCR) et la compréhension de documents complexes à partir d'images. Idéal pour numériser des factures ou extraire des données sensibles.ministral-3:8b: Mistral est toujours impressionnant avec sa famille Ministral 3, conçue pour le déploiement local. La version 8B offre un excellent compromis entre taille en mémoire et capacités de raisonnement. Je l'utilise pour avoir des réponses différentes de temps en temps.llama3.1:8b: Pour les requêtes simples et rapides; excellent pour améliorer le texte français ou anglais, sans utiliser trop de mémoire.
Pour les installer, une fois vos services lancés :
./control.sh ollama pull gemma4:e2b
./control.sh ollama pull glm-ocr:latest
./control.sh ollama pull ministral-3:8b
./control.sh ollama pull llama3.1:8b
En conclusion
En somme, l'architecture que nous venons de monter illustre parfaitement l'efficacité, mais surtout la simplicité. En agençant des logiciels gratuits et open source, on se retrouve avec une interface digne des meilleurs outils commerciaux, propulsée directement par votre carte graphique.
Vous pouvez travailler hors-ligne, et vous avez surtout la certitude que rien ne quitte votre machine.